pandasはRDBを扱う機能は持っていないようです。
が、持っている機能を使えばRDB風に扱うこともできます。
ここで使用するのが、
DataFrame.merge
です。
さっそく使い方について見ていきます。
環境
- VSCode
- python 3.11.0
使用するライブラリ
- pandas
パッケージのインストール方法についてはこちら
データの準備
簡単なRDB風のデータ構造を作ってみます。
| 社員番号 | 社員情報ID |
|---|---|
| str | int |
| 社員情報ID | 社員名 | 所属部署ID |
|---|---|---|
| int(主キー) | str | int |
| 所属部署ID | 所属部署名 |
|---|---|
| int(主キー) | str |
上記のようなRDBとします。
import pandas as pd # 社員番号 employees = pd.DataFrame({ "emp_id" : [123, 456, 789], "info_id" : [3, 2, 1] }) # 社員情報 emp_info = pd.DataFrame({ "info_id" : [1, 2, 3], "name" : ["超ひも", "シュレディンガー", "猫"], "div_id" : [11, 12, 10] }) # 部署 div = pd.DataFrame({ "div_id" : [10, 11, 12], "div_name" : ["営業", "事務", "開発"] })
データの準備ができました。
主キーでつなげる
複数のテーブルを主キーで結合して、ひとつのViewをつくります。
ここで使うのがDataFrame.mergeになります。
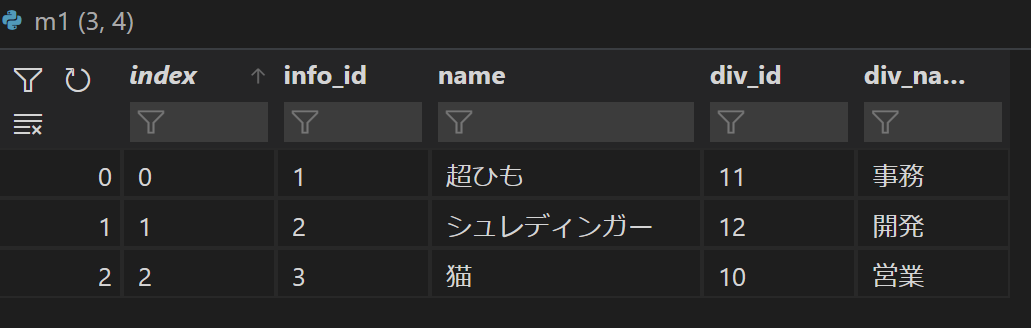
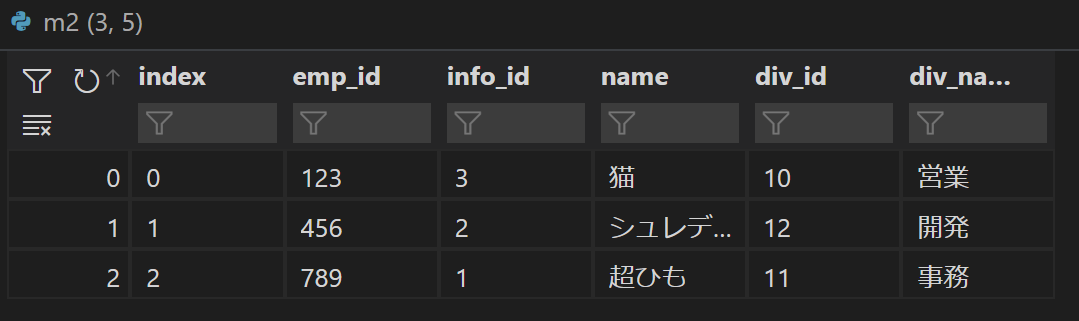
# 社員情報と部署をマージ m1 = emp_info.merge(div, on="div_id") # 社員番号とm1をマージ m2 = employees.merge(m1, on="info_id")
結果を表示してみると以下のようにonで指定したIDをもとに結合されているのがわかります。
ちなみにmerge()のシグネチャは以下の通りです。
def merge( self, right: DataFrame | Series, how: str = "inner", on: IndexLabel | None = None, left_on: IndexLabel | None = None, right_on: IndexLabel | None = None, left_index: bool = False, right_index: bool = False, sort: bool = False, suffixes: Suffixes = ("_x", "_y"), copy: bool = True, indicator: bool = False, validate: str | None = None, ) -> DataFrame:
おしまい
RDBのViewが作れれば、データ解析も捗りそうです。 (追記)こちらの記事を見れば、より捗ることがわかりました。

